

IfcOpenShell / Python - get_local_placement for .ifcElementAssembly

Hi, I am using --> elements = ifc_select.by_type('IfcElement') and ifcopenshell.util.placement.get_local_placement(element.ObjectPlacement) to retrieve X/Y/Z coordinate for all elements.
Results are as expected for all items with exception of 'IfcElementAssembly' types which are all being returned as 0,0,0. Is there a different call required to retrieve the location matrix for these object types?
Tagged:
Comments
What you're doing is correct. It may simply be that the BIM tool has chosen to export those at 0,0,0. Depending on the BIM platform, this can happen in other cases too, like for certain MEP types in Revit. It's just poor quality and should be reported back to the vendor.
Thanks @Moult - doesn't look to be the case, the IfcElementAssembly level all have no zero coordinates being reported in BIMVision (unless these are being made up via another means...?) - see attached....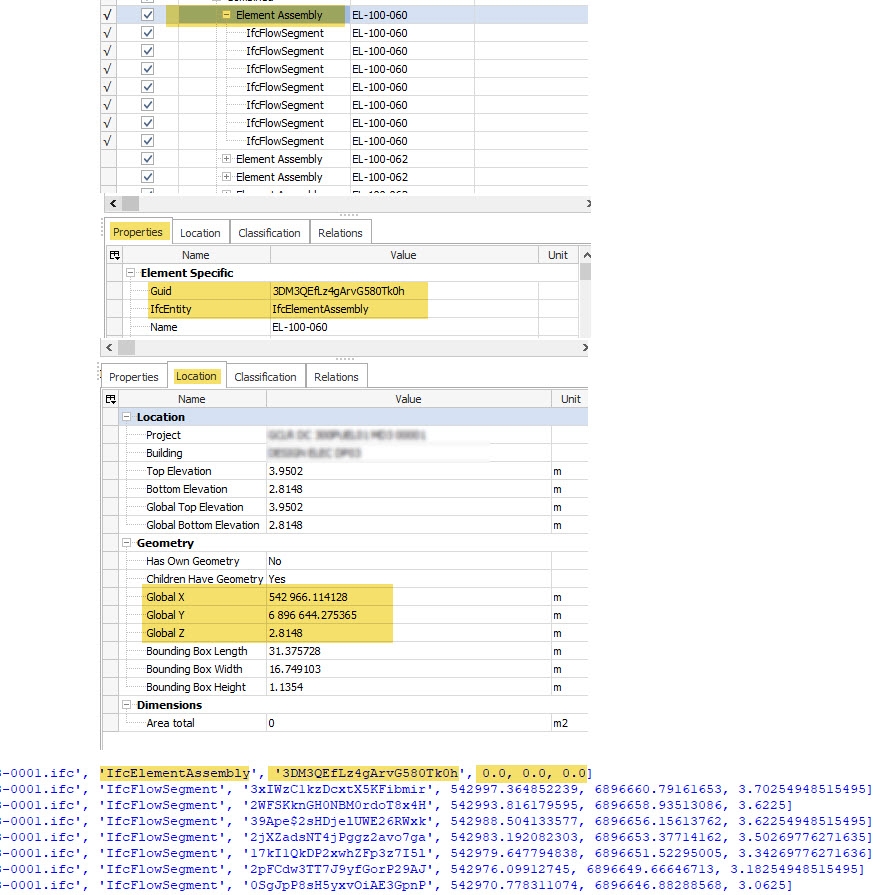
PS - out of interest is there a way to retrieve the 3 values (Bounding Box, L/W/H) directly without calculation using IfcOpenShell ? Will keep looking...
Yeah there are a few possibilities: 1) BIMVision is making it up 2) The placement is grid based or something which isn't yet implemented or 3) there is a bug with get_local_placement (unlikely). To know which it is for sure, I'd need to look at the file, at least the IDs which are related to that placement. Can you share your file, or have a screenshare session to look at it together?
Happy to do either, share file or screen share. Much appreciated....
Fileshare to [email protected] or screenshare by pinging me on the OSArch.org/chat chatroom.
Thanks, I can confirm it's 1) BIMVision is making it up. Here's the exact definition in the IFC:
This means that your file has coordinates that are both close to zero and very far away from zero. This is incorrect coordinate use and in any IFC platform which shows all object data / allows authoring of geometry, this will be a problem (but not for viewers which only display surface geometry and that's it). More reading here: https://blenderbim.org/docs/users/georeferencing.html#incorrect-coordinate-use
Thanks Dion. Ok not going mad.... My cunning plan is back to the drawing board.
Out of interest,
1. Are the "Bounding Box X/YZ" values also "made up / derived" (see image above). And if not are you able to shed some light on how to retrieve using IfcOpenShell?
2. Apart from 'GlobalId' can you think of any other unique identifier or way to derive that an object's geometry in FileA.version1 is exactly the same as an object's geometry in FileA.version2 (noting I am only concerned with geometrical extents when considering a 'match')? Use case is authoring applications reassigning new Ifc GlobalId as geometry is 'recreated' each week but no change to file other than element GlobalIDs. eg 12d trimesh scripts - geometry recreation.
PS - will also be tackling the coordinate use re export setup but may not be able to influence at this stage. I would have thought that the IfcFlowSegments though would have issues with their coordinates (like the ifcElementAssembly) but doesn't seem to be the case in this file.
Your model does not have any bounding boxes explicitly defined, so they are definitely derived. In Python, there aren't yet convenience functions exposed to quickly get the bounding box, but a min() max() run on the points returned by the geometry iterator will get you a bounding box, though it may not be as fast as C++.
For 2, geometric extents agnostic of geometric paradigm are most coarsely described via a bounding box with a tolerance.
If the geometric paradigm is consistent between revisions but the GlobalIds are not, you may do more detailed checks similar to how IfcDiff compares objects for geometry differences. You can't use all of IfcDiff's code directly since it uses GlobalIds to find pairs, but if you find another way to do pairs (placements? geom tree select_by_box?) then you can use that approach.
I reckon the geom tree would be a good approach if you're totally blind on GlobalIds - build a tree of one file, and use that tree to select objects from another file and see if the object counts match. It's effectively the same approach used in clash detection, and you can see some sample code in IfcClash: https://github.com/IfcOpenShell/IfcOpenShell/blob/v0.7.0/src/ifcclash/ifcclash/collider.py on how to build the trees and collide.
Many thanks for your guidance Dion! I'll take a look at the geom tree approach, and add to this thread if I have any luck.
ok...... so in an attempt to track changes to element locations between file versions when GlobalId can not be used, my initial attempt / logic was as follows,
1. Use the explicitly defined coordinate for each element unless 0,0,0
2. Else use the geometry iterator to create verts and calculate the midpoint of the min/max points .
Where this gets messy is for entities that have related (child) elements eg IfcElementAssembly --> if element.IsDecomposedBy != ()
This is because if the location coordinate isn't explicitly defined (ie 0,0,0) eg for say an IfcElementAssembly, then geometry iterator of no use (as I assume this is because the element doesn't have its own geometry). So to deal with this for above scenario I attempted the following -->
3. For element.IsDecomposedBy[0].RelatedObjects, if relobjs has defined location coordinates then find min / max of these and use midpoint of these midpoints as the parent object's location coordinate. Otherwise if child elements are also 0,0,0 then use object iterator calculated midpoint for each child and calculate the midpoint of midpoints as the parent's location coordinate.
3. Then compare these midpoint coordinates (along with other markers such as element class / name / file name) to generate matches between say V1 to V2 of the file.
So, I am attempting to use each element's location as a primary indicator of "change" between file versions. (not interested in property changes in this scenario). Absolute coordinates are not critical either in this case, rather relative change in coordinates from version to version so I think generally speaking above may have legs (in theory).
The main issue I have is time it takes to process across many 100's of files. I am only learning python and ifcopenshell so I know there will be significant gains to be made with changes to how my code is written. That aside, the other main contributor to bloated processing times is definitely item 3 . I would appreciate any thoughts on how to better deal with these have.RelatedObjects elements such as IfcElementAssembly given their coords may or may not be explicitly defined (and their child elements may also not have coordinates explicitly defined). @Moult ? others?
Any geometry processing using the iterator can have significant slowdowns in processing time, so I would assume step 2 to be the bottleneck, not step 3. I would make a queue of elements that need to run through the iterator and run the iterator as late as possible using the
includekeyword argument to save time. Also make sure you are using multicore with all your CPUs.Any aggregate object (such as IfcElementAssembly) will never have its own geometry, so you are correct to check its child elements.
Depending on how you are correlating coordinates you may wish to use Python sets, not lists, or k-d trees. This is all speculative though, best if you shared some code online for us to take a look.
Also would be good for you to profile your code, not assume where the bottlenecks are.
Instead of processing all N elements in file X and all M elements in file Y, and then comparing N with M, it may also be more efficient to batch process grouped by IFC class / name. Any algorithm which has exponential processing time would then also be significantly faster. E.g. if you have 200 walls in file X and 250 walls in file Y, after you've exhausted checking 200, the remaining 50 are definitely changes (i.e. additions) and no expensive checks need to be done.
Thanks Dion, yes after this post I stripped back to just the geom iterator loop only and found that for some files that are small ~3Mb took circa 2-5secs per file but there were others of same size (and similar number of elements) that took 10x the time. I couldn’t see a pattern. For large -100Mb + this again appeared random with regards to processing time (to me anyway). One taking 10+mins… so yes the iterator is expensive for some but not all (?) and I’ll need to try and understand why as currently not viable. (Yes using multi core for iterator).
Do recall reading something about garbage collection when accessing aggregate child elements when using iterator also??
Yes have been using lists / numpy mostly so will try and understand how to use python sets or k-d trees but the compare routine is currently fast (enough). Writing results to file and using pandas dataframes to compare week to week results.
It is the generation of the initial baseline element/aggregate coordinates that needs the attention.
Out of interest is there any other strategy that might be worth testing do you think or generating vertices using the geom iterator pretty much the only way if coords not explicitly defined. ?
Will share some code when back in few days.
Thanks again for your input..! I am battling my way line by line…
If coords are not explicitly defined, unfortunately there isn't much else you can do except for use the iterator. If they had a box representation context, that would be ultra fast, but unfortunately most people don't include box representations (especially Revit is notoriously slow at generating them, despite the "include box representation" being enticingly easy to enable).
Long iterator processing times are either due to high poly counts or complex booleans. Booleans are largely unnecessary in your check I believe and can either be semantic booleans (e.g. opening elements) or unsemantic (e.g. CSGs). For the semantic ones you can enable DISABLE_OPENING_SUBTRACTIONS in the iterator settings. For the unsemantic ones, well, scold the original author is the best you can do perhaps unless you want to arbitrarily patch the CSG tree to the first shape.
For high poly counts those are likely just breps/tessellations. For your usecase it would be much faster to simply process the IfcCartesianPoints directly and skip the iterator for those elements. This example shows how to isolate faceted breps and FBSM. You can write similar for tessellated face sets. Then use get_info_2() on the shape representation to get all of the coordinates which you can loop through in regular Python. More work, but much faster.