

ai-chat.ifcopenshell.org is live!

I just pushed the first version of https://ai-chat.ifcopenshell.org/ online!
This is based on bruno's remarkable ifcmcp work. But then with a web-based assistant-like interface around it. Fully browser-based. See https://github.com/IfcOpenShell/IfcOpenShell/pull/7660
Currently BYOT (bring your own token) OpenAI-only because of laziness. That's bad, but it's more of a demonstrator.
The usefulness you can get out of this even today is really amazing. If you haven't already tried the full ifcmcp I really recommend to have a look.
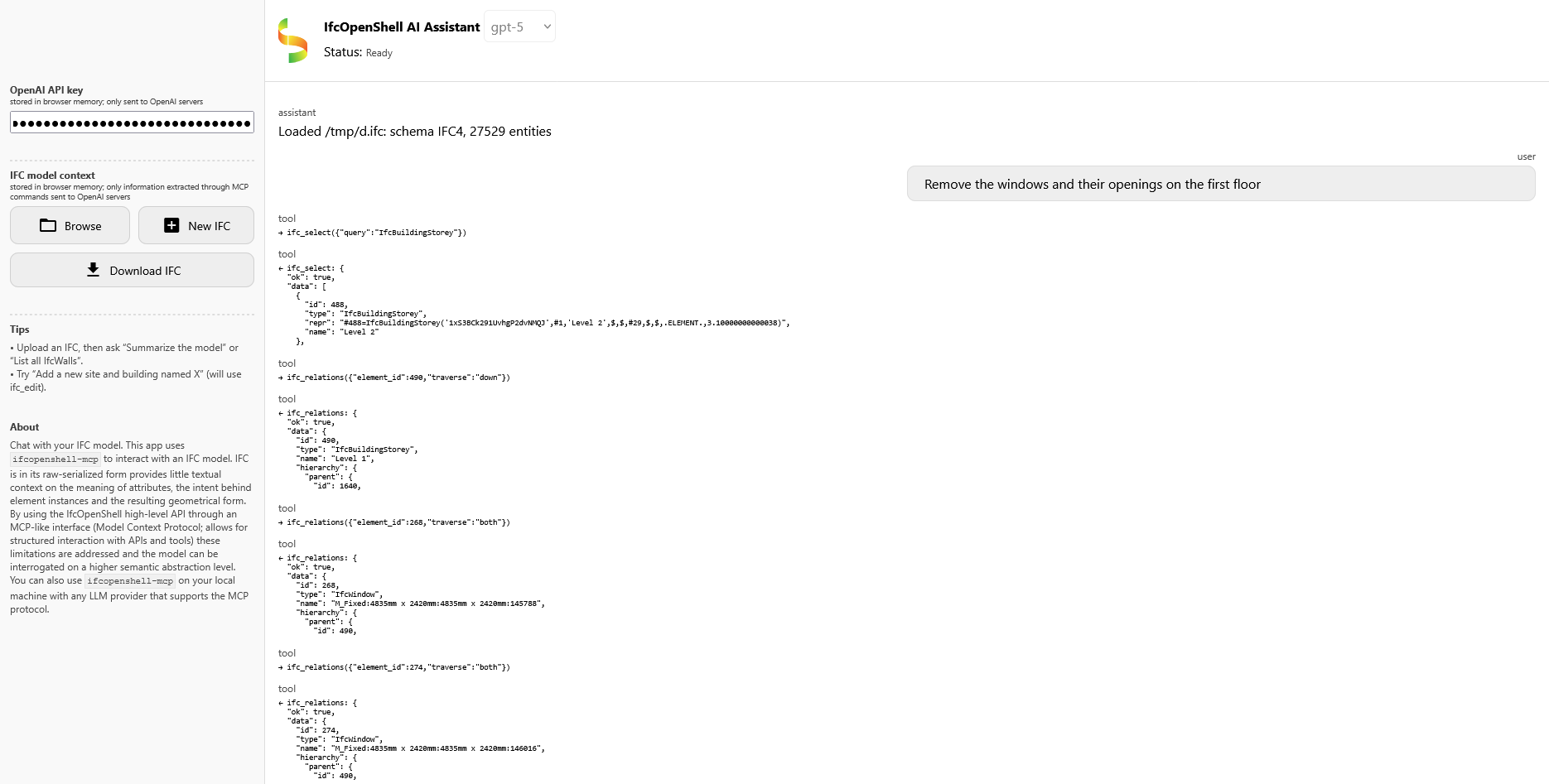
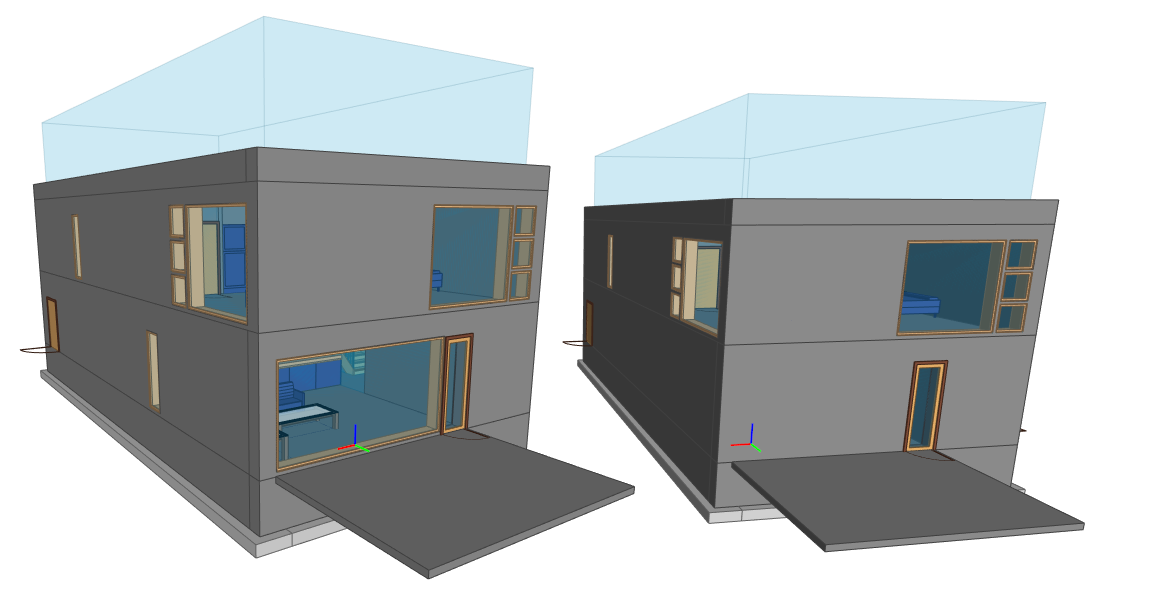
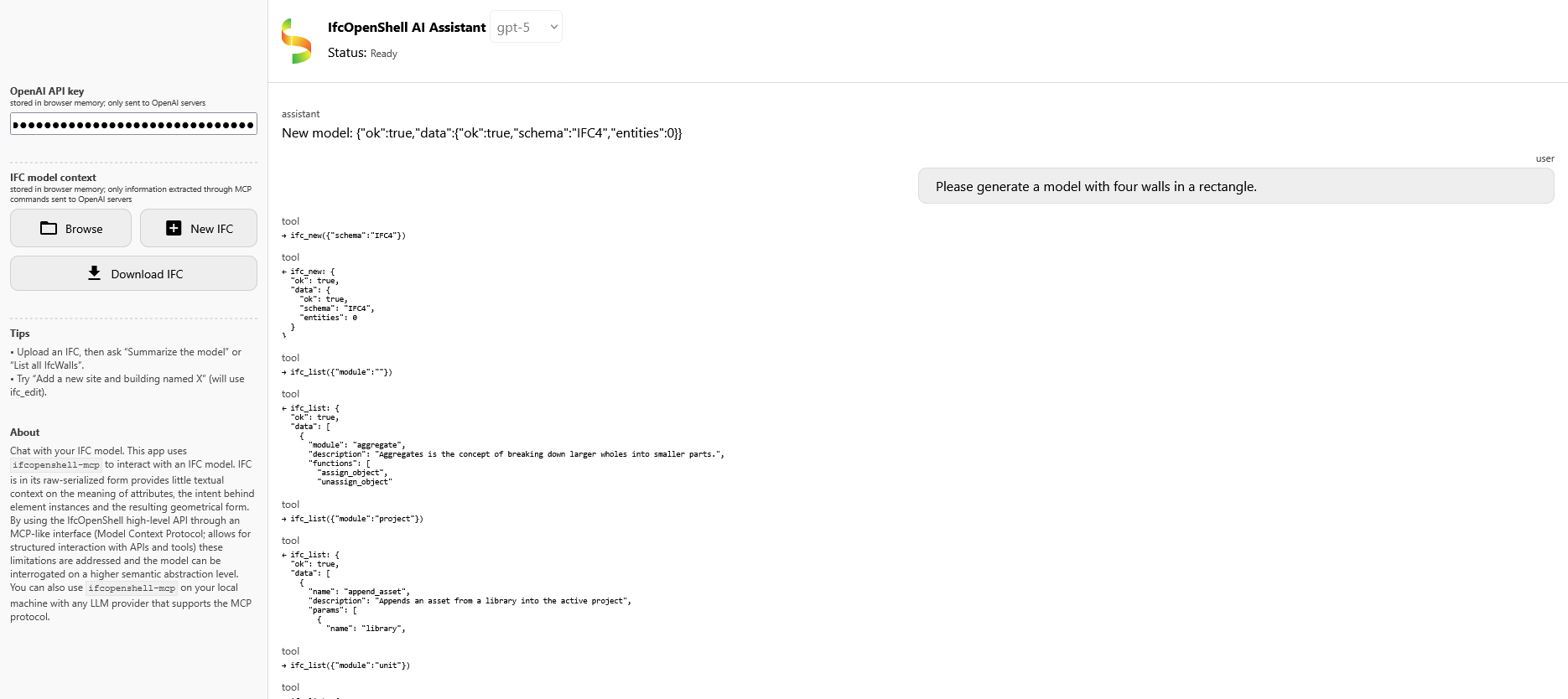
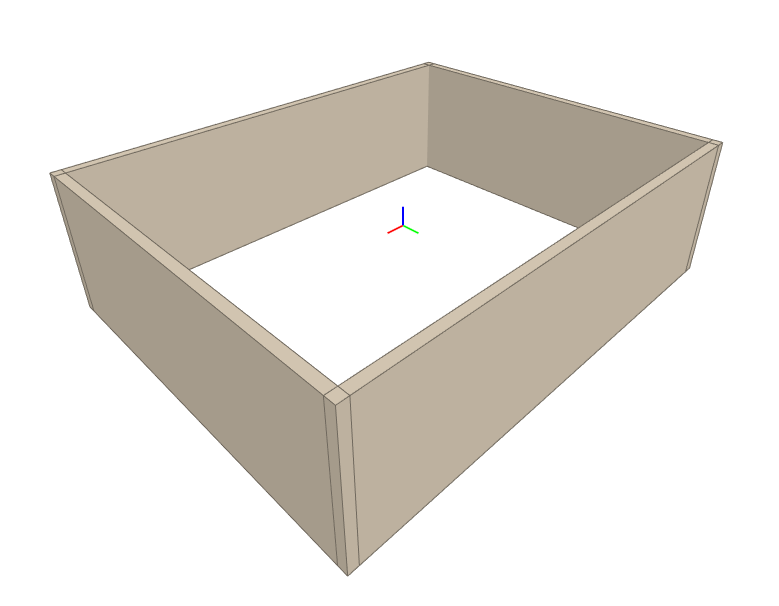








 and 4 others.
and 4 others.
Comments
very cool!
Possible to add a Claude key too?
Maybe ask Claude to add it: https://github.com/IfcOpenShell/IfcOpenShell/tree/v0.8.0/src/ifcchat cannot test myself. It's not only the token, it's also the API calls: https://github.com/IfcOpenShell/IfcOpenShell/blob/fb81c88a5f03f2dc4a11d5c93aadb990eac06981/src/ifcchat/app.js#L162
Cool, will try.
Claude Code got it set up for me pretty quickly. Playing around with it now!
@myoder89 cool, can you push the change as a PR? Thanks.
someone provided OpenRouter support.
That's cool.
https://github.com/IfcOpenShell/IfcOpenShell/pull/7896
Sorry for the wait everyone. PR for addition of Claude is here, let me know if you have any issues:
https://github.com/IfcOpenShell/IfcOpenShell/pull/7897
Thanks all. Really looks a bit better with provider selection.
I have credits, but Claude cried when I fed the following prompt, on the following model.
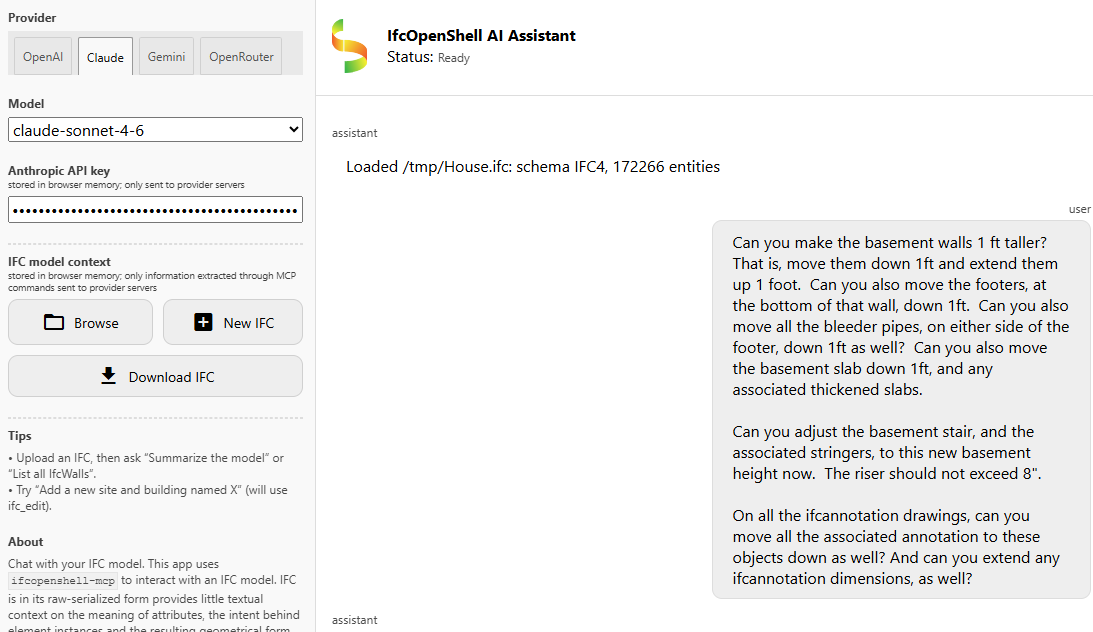
https://hub.openingdesign.com/OpeningDesign/Bonsai_Tutorials/src/branch/main/_Model/House.ifc
It even cried when I shortened the prompt to 'just make the basement walls taller'.
30_000 tokens per minute sounds like something you would burn through pretty quickly, but I also don't see a real monster in terms of output. If it's really minute based then I think the most likely way out is to introduce a small delay in terms of the tool call iterations so that you spread out the execution over a longer period of time.
I don't have much experience building these kind of apps. Curious what others say. The fact that you send the full history for every message does sound a bit awful in terms of non-linearity.
Edit: what I did is capture the body before being sent. That was about 1000 words, so approx 3000 tokens (?). But that's a single message. With all these tool calls + full history that quickly adds up.
I had Claude review and it pointed out a few things that could improve the token usage per prompt. I tested locally and it seems to have greatly improved what ChatIOS here can handle. Here's the link if folks want to test it out. Fair warning, this was a 100% "vibe" on my part.
https://github.com/IfcOpenShell/IfcOpenShell/pull/7904
Thanks!
Well, at worst, that moves the total vibe percentage up from 95 to 96% ;)
Assuming these latest changes were applied, i still get the following, with the same prompt and file, as mentioned above.

There is now also compaction, i.e using the llm to summarise the message trail to reduce tokens and some client-side throttling / rate limiting to keep track of the estimated amount of input tokens per minute bucket and if at limit defer to the next minute.
I'm curious if you get better results now @theoryshaw your case still appears to be somewhat advanced, but it would be interesting to see what's needed to get this to work:
It's probably better if you use ifcmcp directly though because I imagine the kind of compaction and throttling is built in if you use their official client.
Yeah, unfortunately, got the same error, even with...
Can you make the basement walls 1 ft taller? That is, move them down 1ft and extend them up 1 foot.