for row in worksheet_openpyxl:
if worksheet_openpyxl.row_dimensions[row[0].row].hidden == False:
for cell in row:
if cell in worksheet_openpyxl['A']:
global_id_filtered_list.append(cell.value)
You're iterating over each row, then iterating over each cell in the row, then checking if the cell is in the first column. You can just iterate over each row index, thus not needing to retrieve a cell object with all the columns, and simply checking if the row is not hidden by index, then access the cell with a string accessor. As long as the GlobalId is in the first column and the values start on row 3 this should work :
for row_idx in range(3, worksheet_openpyxl.max_row + 1):
if not worksheet_openpyxl.row_dimensions[row_idx].hidden:
cell = worksheet_openpyxl[f"A{row_idx}"]
global_id_filtered_list.append(str(cell.value))
I didn't time the difference because it was so long it didn't even compute within a few minutes with the before version on my computer. Using the after version, it computes in roughly 2 seconds, most of which is taken by loading the file in memory as far as I can tell.
I used the logic from this q&a from SO : https://stackoverflow.com/a/40027305
Also this gets rid of a potentially inefficient list slicing that runs for every ifc object a few lines lower :
obj.hide_viewport = data.get("GlobalId", False) not in global_id_filtered_list[1:]
That you can replace with
obj.hide_viewport = data.get("GlobalId", False) not in global_id_filtered_list
@Coen
'Well, I didn't do it alone. I just based my idea on work of others. :-)'
therein lies the achievement, making good use of what is already available
@Coen perhaps when you feel the time is right, would you feel comfortable with writing up an article to be published on OSArch.org showcasing what you've achieved? It would be a fantastic thing to share with the community.
Also, good catch with the lack of Open Document format support on this forum! I've now added support for ODS, ODT and ODP.
@Coen I'm a bit confused by the lack of possibility to tinker with .ods files using a python module. Pandas is nice to extract data, but I'd expect to be able to extract smart data. :)
After some digging around and reading some discussions about the subject I found a .ods is basically a zip file containing some xmls. Using this handy parser I've constructed a simple(r) parser that outputs a list of rows (o-based index) that are hidden.
# Import the needed modules
import zipfile
import xml.parsers.expat
# https://www.stefaanlippens.net/opendocumentpython/
# Get content xml data from OpenDocument file
ziparchive = zipfile.ZipFile(r"C:\Path\To\My\File.ods", "r")
xmldata = ziparchive.read("content.xml")
ziparchive.close()
class Element(list):
def __init__(self, name, attrs):
self.name = name
self.attrs = attrs
class TreeBuilder:
def __init__(self):
self.root = Element("root", None)
self.path = [self.root]
def start_element(self, name, attrs):
element = Element(name, attrs)
self.path[-1].append(element)
self.path.append(element)
def end_element(self, name):
assert name == self.path[-1].name
self.path.pop()
def char_data(self, data):
self.path[-1].append(data)
def get_hidden_rows(node):
row = 0
for e in node:
if not isinstance(e, Element):
continue
yield from get_hidden_rows(e)
if e.name != "table:table-row":
continue
attrs = e.attrs
rows = int(attrs.get("table:number-rows-repeated", 1))
if "table:visibility" in attrs.keys(): # If the key is here, we can assume it's hidden (or can we ?)
for row_idx in range(rows):
yield row + row_idx
row += rows
# Create parser and parsehandler
parser = xml.parsers.expat.ParserCreate()
treebuilder = TreeBuilder()
# Assign the handler functions
parser.StartElementHandler = treebuilder.start_element
parser.EndElementHandler = treebuilder.end_element
parser.CharacterDataHandler = treebuilder.char_data
# Parse the data
parser.Parse(xmldata, True)
hidden_rows = get_hidden_rows(treebuilder.root) # This returns a generator object
print(list(hidden_rows))
I'm sure it can be optimised but it seems to do the job. I expect you can directly feed this list into pandas.read_excelskiprows argument.
A bit of explanation : Basically at the end of the context.xml file inside the ods archive, there are a bunch of definitions. If a row is hidden it will have a table:visibility="collapse" key / value. The rows are described from index 0 to infinity or until the last hidden row is defined. When two or more rows in succession have the same state a flag is added to the first row definition eg table:number-rows-repeated="3". From that we can iterate over all the row definitions and simply extract the rows that interest us.
Hope that helps ! If you need help implementing it into your add-on don't hesitate to ask.
perhaps when you feel the time is right, would you feel comfortable with writing up an article to be published on OSArch.org showcasing what you've achieved? It would be a fantastic thing to share with the community.
You mean a technical article? Or personal? Or a tutorial?
@Gorgious
Thank you so much! I was really getting desperate, trying all kind of obscure python modules like pyexcel-ods and others to no avail.
I really was looking on how to modify the xml in the zip file. Turns out it comes standard with python. I implemented your pointers. Now it's possible to filter from an .ods file as well. :-D. I commited the code and added a new zip today.
After @duncans LinkedIn promotional activity, I got about 35 unique views on my Github page.
and I got a pull request from a github user called denizmaral. He pointed out the file would not open on MacOS and I approved his request. I have no way to test this obviously. It works on Windows 10, so if you read this, thank you :-)
I wanted to test if the add-on will work on Linux Ubuntu, so far so good:
But when I checked the add-on I get the following error: ModuleNotFoundErro: No modude named 'pandas.libs.interval'
Need to see how I can fix this.
Also I think the way @Gorgious reads the xml file I think can also look for a method on how to apply the autofilter in the xml file. Making the assumption it happens in the content.xml. As I asked here on SO
Some screenshots from filtering from an .ods file.
Manually applying the autofilter in LibreOffice
Now possible to filter in Blender
And in general I did some refactoring, added new functions and tried to clean up the script a bit.
Thanks everyone for the help and testing so far.
... since Excel claims to read .ods files (it reads them fine as far as I know) maybe the .xlsx export could even be dropped instead of trying to maintain function parity. Just saying.
Nice !! Yeah we can investigate how the custom filters are handled in ods. Writing data will be more troublesome than parsing it, but it's definitely doable. A minimal working file with something like 2 columns and 2 rows and a filter should yield the precious lines at the bottom of the xml file if I'm not mistaken. After that it's "just" a matter of copying it correctly when writing the file back, without messing things up :)
Hi Cohen,
Congratulations for your work. I think is a very good complement to Blende Bim.
I'm testing your addon and get an error with a model imported from here (the first model; the others I tested worked well): https://ifcinfra.de/ifc-bridge/bridge-abschluss/#beispielmodelle
Export to "ods" format doesn't work and get the follow error:
location: :-1
Error: Python: Traceback (most recent call last):
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\BlenderBIMSpreadsheet.py", line 467, in execute
construct_data_frame = ConstructDataFrame(context)
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\BlenderBIMSpreadsheet.py", line 149, in init
ifc_dictionary['Classification'].append(self.get_classification_code(context, ifcproduct=product)[0])
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\BlenderBIMSpreadsheet.py", line 249, in get_classification_code
assembly_code_list.append(ifcproduct.HasAssociations[0].RelatingClassification.ItemReference)
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\blenderbim\libs\site\packages\ifcopenshell\entity_instance.py", line 122, in getattr
raise AttributeError(
AttributeError: entity instance of type 'IFC4X2.IfcClassificationReference' has no attribute 'ItemReference'
maybe is a problem with the ifc sample but it wild be good to "skip" this questions to obtain the spreadsheet file. Now, the process stop without results.
Thanks for the feedback, don't know when you downloaded the add-on. Because I fixed this bug two hours ago. If you get the latest version this error should dissappear. I discovered classification works a bit different in IFC4.
I fixed it like this, If anyone has any tips on how to improve it's highly appreciated. :-)
if ifcproduct.HasAssociations:
if ifcproduct.HasAssociations[0].is_a() == 'IfcRelAssociatesClassification':
if ifcproduct.HasAssociations[0].RelatingClassification:
#for IFC2x3
if ifc_version == 'IFC2X3':
if ifcproduct.HasAssociations[0].RelatingClassification.ItemReference:
assembly_code_list.append(ifcproduct.HasAssociations[0].RelatingClassification.ItemReference)
#for IFC4
if ifc_version == 'IFC4':
if ifcproduct.HasAssociations[0].RelatingClassification.Identification:
assembly_code_list.append(ifcproduct.HasAssociations[0].RelatingClassification.Identification)
if ifcproduct.HasAssociations[0].is_a() == 'IfcRelAssociatesMaterial':
for i in ifcproduct.HasAssociations:
if i.is_a() == 'IfcRelAssociatesClassification':
#for IFC2x3
if ifc_version == 'IFC2X3':
if i.RelatingClassification.ItemReference:
assembly_code_list.append(i.RelatingClassification.ItemReference)
#for IFC4
if ifc_version == 'IFC4':
if i.RelatingClassification:
assembly_code_list.append(i.RelatingClassification.Identification)
This is a bit outside of the scope of BlenderBIM so I will keep it short. I looked at several ways on how to apply an autofilter in LibreOffice. I asked the question on Stack Overflow. But no response. I am really stuck here.
On the other hand, I really would like to start integrating this add-on in the BlenderBIM add-on. I would like to do the communication about this out in the open, in this thread.
What I think I need to do first,
1. rewrite the add-on so it consists of an ui.py and operator.py?
2. git clone the ifcopenshell repo which contains blenderbim add-on?
3. start writing my code in there and do a pull request?
4. refactor the script
From now on I only will be able to work on the weekends on this project. No more lockdown, yay!
I have little to no expierence with collaboration on a software project. So I will ask a lot of noob questions.
Also, I barely got any feedback from people who use it. But I can see from my insights repo on github ithe following:
So, I think integrating it in the BlenderBIM add-on will expose way more users to this feature.
Last funny fact, from my Youtube Analytics I can see most viewers from the demo video are located in France, which I did not expect.
From my very limited experience in software development, I'd say not having feedback is not always a bad thing, it may just mean that there is no bugs and people find it easy enough to use that they don't need any other information.
I think the integration into Blenderbim should be pretty straightforward, but you'd need to do some basic refactoring, mainly separating the UI code from the logic code, and also the operator code. You can snoop around in the existing blenderbim codebase and try to mimick a simple enough module and see where that gets you. Don't hesitate to post questions, open issues or discussions, it can benefit anyone ! It can be done iteratively. You can clone the github repo, create a new branch, make your changes on your local fork and create a PR even if it's not yet totally ready for merging, it can be helpful for other people to review your code by just cloning your branch then.
You'd also want to write some unit tests, but that can be arranged later I think.
@Gorgious said:
Well you can count me in these 2.1% ^^
From my very limited experience in software development, I'd say not having feedback is not always a bad thing, it may just mean that there is no bugs and people find it easy enough to use that they don't need any other information.
I think the integration into Blenderbim should be pretty straightforward, but you'd need to do some basic refactoring, mainly separating the UI code from the logic code, and also the operator code. You can snoop around in the existing blenderbim codebase and try to mimick a simple enough module and see where that gets you. Don't hesitate to post questions, open issues or discussions, it can benefit anyone ! It can be done iteratively. You can clone the github repo, create a new branch, make your changes on your local fork and create a PR even if it's not yet totally ready for merging, it can be helpful for other people to review your code by just cloning your branch then.
You'd also want to write some unit tests, but that can be arranged later I think.
Correct, it works and is discoverable?? no problem
Could it be useful as a standalone desktop app? Maybe it first finds all the ifc classes in a file and the user tick boxes the required output and press Go, the spreadsheet opens magic!
Read prefs: C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\config\userpref.blend
Traceback (most recent call last):
File "C:\Program Files\Blender Foundation\Blender 3.1\3.1\scripts\modules\addon_utils.py", line 351, in enable
mod = __import__(module_name)
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\BlenderBIMSpreadsheet.py", line 32, in <module>
import pandas as pd
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\libs\site\packages\pandas\__init__.py", line 22, in <module>
from pandas.compat import (
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\libs\site\packages\pandas\compat\__init__.py", line 15, in <module>
from pandas.compat.numpy import (
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\libs\site\packages\pandas\compat\numpy\__init__.py", line 7, in <module>
from pandas.util.version import Version
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\libs\site\packages\pandas\util\__init__.py", line 1, in <module>
from pandas.util._decorators import ( # noqa
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\libs\site\packages\pandas\util\_decorators.py", line 14, in <module>
from pandas._libs.properties import cache_readonly # noqa
File "C:\Users\cclaus\AppData\Roaming\Blender Foundation\Blender\3.1\scripts\addons\libs\site\packages\pandas\_libs\__init__.py", line 13, in <module>
from pandas._libs.interval import Interval
ModuleNotFoundError: No module named 'pandas._libs.interval'
I wonder if that only happens on my system, I have windows 10 with Python 3.9 installed. Does it default to my standard python installation?
Anyone else tried to install the BlenderBIM spreadsheet add-on on Blender 3.1.0?
@Ace
Thanks for the feedback, I needed to install the third party modules from Blender 3.1.0 again, because it's a different Python version (obviously).
I zipped the add-on for 3.1.0 and pushed it to Github, new version to be found here:
I'd encourage you to start your installer with a check for the needed dependencies and come with a warning for users. We've had this problem with a few addins to blender which needed something as simple as numpy - it just happened that I didn't have it installed but knew how to.
Hi!!
Congrats and a huge thank you for all your work!!!
I've just started using the spreadshets addon, and have some issues with it not exporting custom parameters to excel.
I'm using the syntax Psetname.PropertyName, and it doesn't give any errors, but only exports general properties.
Any clues on what's happening? I'm in blender 3.1.
Thanks in advance!!!!
@Javier_Gutierrez
I see, I'm not too familiar with Linux distributions. You could try to install python pandas by opening the scripting console in Blender and run this script
I just tried to make an export from the Schependomlaan in Blender 3.1.2 with this version of BlenderBIM spreadsheet installed.
The IfcBuildingStorey does not export anymore to Excel, which is odd,
I have no other IFC files to test, if anyone could do, please :)
I am planning to refactor the BIM spreadsheet script anyway, seperate the script into an operator, ui and prop.
Then I would also like to integrate it with the BlenderBIM add-on. And write good documentation. Because I just looked at the script and get confused about what I wrote a few months ago...
Can I git clone and make a folder here which says spreadsheet?: https://github.com/IfcOpenShell/IfcOpenShell/tree/v0.7.0/src/blenderbim/blenderbim/bim/module
I never really collaborated on an open source project, I need to get familiar with git and the blenderbim architecture.
The BlenderBIM spreadsheet uses quite a lot of 'heavy' modules like xlsxwriter, pandas, ods. Where does BlenderBIM store all these third party dependencies if it's ever going to be integrated?
Plus I have no means and knowledge to test it on mac/linux.


Comments
@Coen Thanks for the file !
I think this is the main offender :
You're iterating over each row, then iterating over each cell in the row, then checking if the cell is in the first column. You can just iterate over each row index, thus not needing to retrieve a cell object with all the columns, and simply checking if the row is not hidden by index, then access the cell with a string accessor. As long as the
GlobalIdis in the first column and the values start on row 3 this should work :I didn't time the difference because it was so long it didn't even compute within a few minutes with the before version on my computer. Using the after version, it computes in roughly 2 seconds, most of which is taken by loading the file in memory as far as I can tell.
I used the logic from this q&a from SO : https://stackoverflow.com/a/40027305
Also this gets rid of a potentially inefficient list slicing that runs for every ifc object a few lines lower :
That you can replace with
@Gorgious
That made a huge difference, thank you very much. I timed the difference with 492 records filtered out in excel in the old way
63.61368060000001 seconds to show the IFC elementsAfter your refactor tips
2.4018126999999936 seconds to show the IFC elementsI committed the code straight away and added a new .zip file.
Done, I think
Let's push this project out a bit wider :-)
https://www.linkedin.com/feed/update/urn:li:activity:6895452758858706944
@Coen
'Well, I didn't do it alone. I just based my idea on work of others. :-)'
therein lies the achievement, making good use of what is already available
@Coen perhaps when you feel the time is right, would you feel comfortable with writing up an article to be published on OSArch.org showcasing what you've achieved? It would be a fantastic thing to share with the community.
Also, good catch with the lack of Open Document format support on this forum! I've now added support for ODS, ODT and ODP.
@Coen I'm a bit confused by the lack of possibility to tinker with .ods files using a python module. Pandas is nice to extract data, but I'd expect to be able to extract smart data. :)
After some digging around and reading some discussions about the subject I found a .ods is basically a zip file containing some xmls. Using this handy parser I've constructed a simple(r) parser that outputs a list of rows (o-based index) that are hidden.
I'm sure it can be optimised but it seems to do the job. I expect you can directly feed this list into pandas.read_excel
skiprowsargument.outputs :
[1, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 38, 39, 40, 41, 42, 43, 44, 51, 52, 53, 54, 55, 56, 57, 58, 59]A bit of explanation : Basically at the end of the
context.xmlfile inside the ods archive, there are a bunch of definitions. If a row is hidden it will have atable:visibility="collapse"key / value. The rows are described from index 0 to infinity or until the last hidden row is defined. When two or more rows in succession have the same state a flag is added to the first row definition egtable:number-rows-repeated="3". From that we can iterate over all the row definitions and simply extract the rows that interest us.Hope that helps ! If you need help implementing it into your add-on don't hesitate to ask.
Cheers
@Moult
You mean a technical article? Or personal? Or a tutorial?
@Gorgious
Thank you so much! I was really getting desperate, trying all kind of obscure python modules like
pyexcel-odsand others to no avail.I really was looking on how to modify the xml in the zip file. Turns out it comes standard with python. I implemented your pointers. Now it's possible to filter from an .ods file as well. :-D. I commited the code and added a new zip today.
After @duncans LinkedIn promotional activity, I got about 35 unique views on my Github page.
and I got a pull request from a github user called
denizmaral. He pointed out the file would not open on MacOS and I approved his request. I have no way to test this obviously. It works on Windows 10, so if you read this, thank you :-)I wanted to test if the add-on will work on Linux Ubuntu, so far so good:
But when I checked the add-on I get the following error:
ModuleNotFoundErro: No modude named 'pandas.libs.interval'Need to see how I can fix this.
Also I think the way @Gorgious reads the xml file I think can also look for a method on how to apply the autofilter in the xml file. Making the assumption it happens in the
content.xml. As I asked here on SOSome screenshots from filtering from an .ods file.
Manually applying the autofilter in LibreOffice
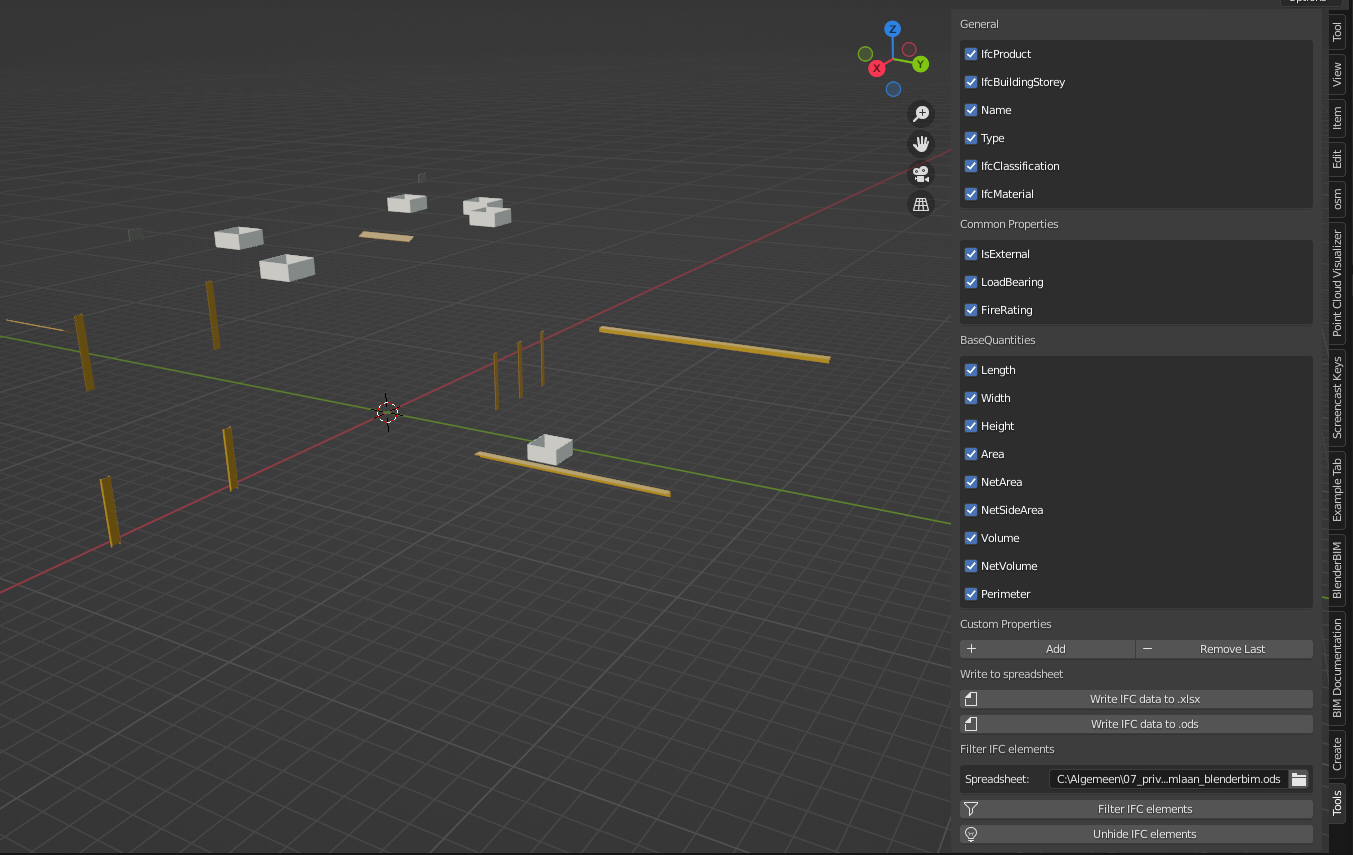
Now possible to filter in Blender
And in general I did some refactoring, added new functions and tried to clean up the script a bit.
Thanks everyone for the help and testing so far.
... since Excel claims to read .ods files (it reads them fine as far as I know) maybe the .xlsx export could even be dropped instead of trying to maintain function parity. Just saying.
Nice !! Yeah we can investigate how the custom filters are handled in ods. Writing data will be more troublesome than parsing it, but it's definitely doable. A minimal working file with something like 2 columns and 2 rows and a filter should yield the precious lines at the bottom of the xml file if I'm not mistaken. After that it's "just" a matter of copying it correctly when writing the file back, without messing things up :)
Btw slight optimisation : You can replace
with
Hi Cohen,
Congratulations for your work. I think is a very good complement to Blende Bim.
I'm testing your addon and get an error with a model imported from here (the first model; the others I tested worked well):
https://ifcinfra.de/ifc-bridge/bridge-abschluss/#beispielmodelle
Export to "ods" format doesn't work and get the follow error:
location: :-1
Error: Python: Traceback (most recent call last):
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\BlenderBIMSpreadsheet.py", line 467, in execute
construct_data_frame = ConstructDataFrame(context)
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\BlenderBIMSpreadsheet.py", line 149, in init
ifc_dictionary['Classification'].append(self.get_classification_code(context, ifcproduct=product)[0])
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\BlenderBIMSpreadsheet.py", line 249, in get_classification_code
assembly_code_list.append(ifcproduct.HasAssociations[0].RelatingClassification.ItemReference)
File "C:\Users\Admin\AppData\Roaming\Blender Foundation\Blender\2.93\scripts\addons\blenderbim\libs\site\packages\ifcopenshell\entity_instance.py", line 122, in getattr
raise AttributeError(
AttributeError: entity instance of type 'IFC4X2.IfcClassificationReference' has no attribute 'ItemReference'
maybe is a problem with the ifc sample but it wild be good to "skip" this questions to obtain the spreadsheet file. Now, the process stop without results.
@avico
Thanks for the feedback, don't know when you downloaded the add-on. Because I fixed this bug two hours ago. If you get the latest version this error should dissappear. I discovered classification works a bit different in IFC4.
I fixed it like this, If anyone has any tips on how to improve it's highly appreciated. :-)
Coen,
I downloaded the addon this morning (spanish time), some hours before the comment. I will continue trying this new version.
@avico
Did it work?
Yes Coen,
In the filters I tested, BlenderBIMSpreadsheet worker well with this model and libreoffice.
Good job, and thanks for your work.
This is a bit outside of the scope of BlenderBIM so I will keep it short. I looked at several ways on how to apply an autofilter in LibreOffice. I asked the question on Stack Overflow. But no response. I am really stuck here.
On the other hand, I really would like to start integrating this add-on in the BlenderBIM add-on. I would like to do the communication about this out in the open, in this thread.
What I think I need to do first,
1. rewrite the add-on so it consists of an
ui.pyandoperator.py?2. git clone the ifcopenshell repo which contains blenderbim add-on?
3. start writing my code in there and do a pull request?
4. refactor the script
From now on I only will be able to work on the weekends on this project. No more lockdown, yay!
I have little to no expierence with collaboration on a software project. So I will ask a lot of noob questions.
Also, I barely got any feedback from people who use it. But I can see from my insights repo on github ithe following:
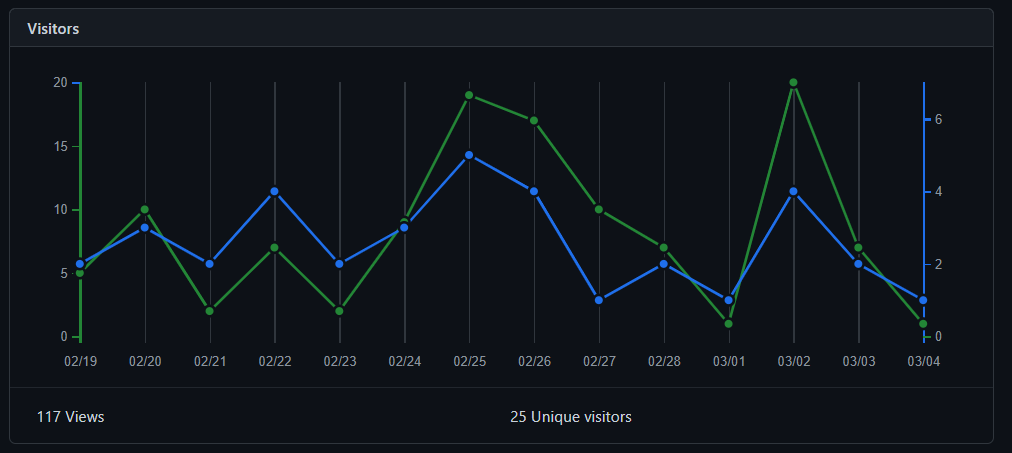
So, I think integrating it in the BlenderBIM add-on will expose way more users to this feature.
Last funny fact, from my Youtube Analytics I can see most viewers from the demo video are located in France, which I did not expect.
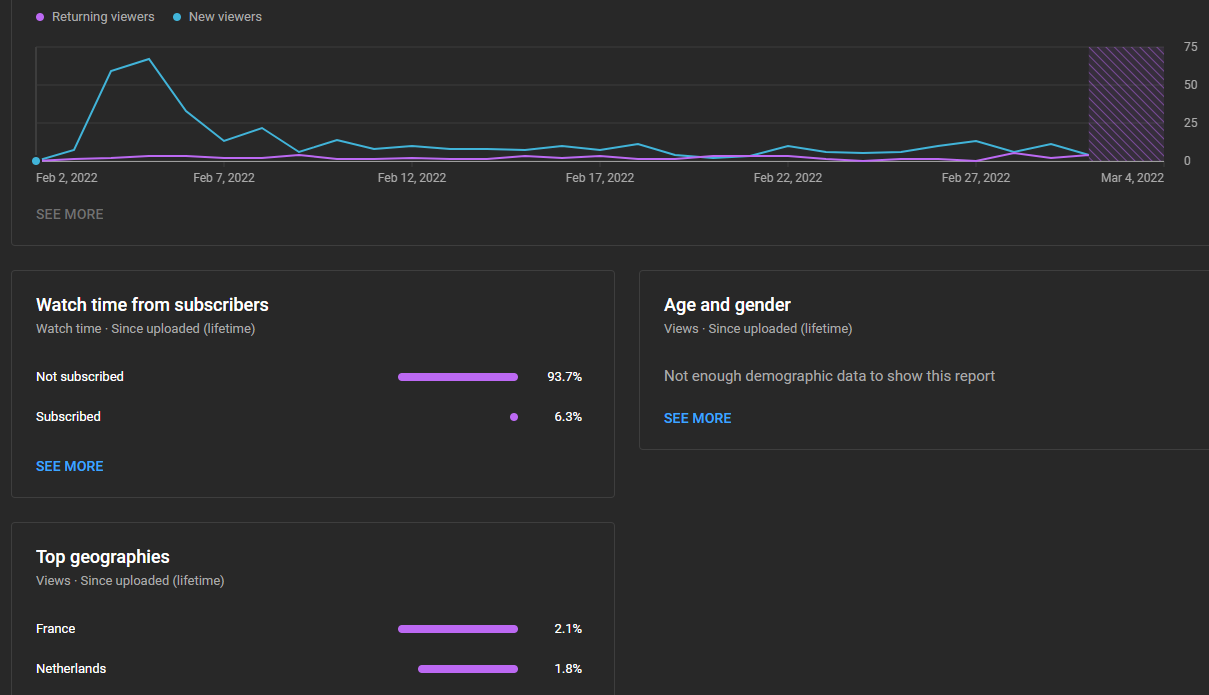
Well you can count me in these 2.1% ^^
From my very limited experience in software development, I'd say not having feedback is not always a bad thing, it may just mean that there is no bugs and people find it easy enough to use that they don't need any other information.
I think the integration into Blenderbim should be pretty straightforward, but you'd need to do some basic refactoring, mainly separating the UI code from the logic code, and also the operator code. You can snoop around in the existing blenderbim codebase and try to mimick a simple enough module and see where that gets you. Don't hesitate to post questions, open issues or discussions, it can benefit anyone ! It can be done iteratively. You can clone the github repo, create a new branch, make your changes on your local fork and create a PR even if it's not yet totally ready for merging, it can be helpful for other people to review your code by just cloning your branch then.
You'd also want to write some unit tests, but that can be arranged later I think.
Correct, it works and is discoverable?? no problem
Could it be useful as a standalone desktop app? Maybe it first finds all the ifc classes in a file and the user tick boxes the required output and press Go, the spreadsheet opens magic!
From the AotearoaNZ representation on your graph
I downloaded Blender 3.1.0 and the latest developer build of BlenderBIM
blenderbim-220330-py310-win.zipWhen trying to Install BlenderBIM spreadsheet.
I get the following error:
I wonder if that only happens on my system, I have windows 10 with Python 3.9 installed. Does it default to my standard python installation?
Anyone else tried to install the BlenderBIM spreadsheet add-on on Blender 3.1.0?
I get the same error with the same setup > @Coen said:
@Ace
Thanks for the feedback, I needed to install the third party modules from Blender 3.1.0 again, because it's a different Python version (obviously).
I zipped the add-on for 3.1.0 and pushed it to Github, new version to be found here:
https://github.com/C-Claus/BlenderScripts/tree/master/BlenderBIMSpreadsheet/3.1.0
Works for me, and also on another machine with Windows 10 installed. :-)
I'd encourage you to start your installer with a check for the needed dependencies and come with a warning for users. We've had this problem with a few addins to blender which needed something as simple as numpy - it just happened that I didn't have it installed but knew how to.
Hi!!
Congrats and a huge thank you for all your work!!!
I've just started using the spreadshets addon, and have some issues with it not exporting custom parameters to excel.
I'm using the syntax Psetname.PropertyName, and it doesn't give any errors, but only exports general properties.
Any clues on what's happening? I'm in blender 3.1.
Thanks in advance!!!!
Is it possible for you to share your IFC file and explictily state which properties you would like to export? ?
Hi, I'm using blender 3.1.2 and when I install it it sends me this message: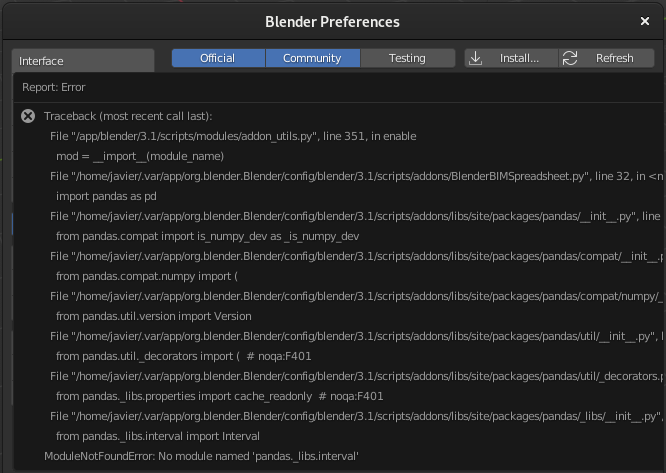
@Javier_Gutierrez it seems it's the exact same error as a few comments up the chain. Have you downloaded the updated version by @Coen ?
yes but I don't know if I'm missing something, I'm working on debian 11, and I downloaded this file
@Javier_Gutierrez
I see, I'm not too familiar with Linux distributions. You could try to install python pandas by opening the scripting console in Blender and run this script
I hope it will install pandas on linux and hopefully the add-on works.
I just tried to make an export from the Schependomlaan in Blender 3.1.2 with this version of BlenderBIM spreadsheet installed.
The IfcBuildingStorey does not export anymore to Excel, which is odd,
I have no other IFC files to test, if anyone could do, please :)
I am planning to refactor the BIM spreadsheet script anyway, seperate the script into an operator, ui and prop.
Then I would also like to integrate it with the BlenderBIM add-on. And write good documentation. Because I just looked at the script and get confused about what I wrote a few months ago...
Can I git clone and make a folder here which says spreadsheet?:
https://github.com/IfcOpenShell/IfcOpenShell/tree/v0.7.0/src/blenderbim/blenderbim/bim/moduleI never really collaborated on an open source project, I need to get familiar with git and the blenderbim architecture.
The BlenderBIM spreadsheet uses quite a lot of 'heavy' modules like xlsxwriter, pandas, ods. Where does BlenderBIM store all these third party dependencies if it's ever going to be integrated?
Plus I have no means and knowledge to test it on mac/linux.
@Coen in BBim there is a module called "demo" that explains how a module works.
You can find more details here:
https://github.com/IfcOpenShell/IfcOpenShell/blob/v0.7.0/src/blenderbim/docs/devs/hello_world.rst
I think this it is very helpful to understand modules behind the scenes and it helped me a lot :-)